How to Structure Content for AI Citation (2026)
You are losing 68% of your web traffic to the AI filter. This is how citation-engineered pages improve clarity, retrieval and reuse to survive AI search.
By Ronan Leonard, Founder, Intelligent Resourcing

Content built for AI citation is not just well written. It is clearly structured so AI systems can understand the topic, retrieve the key point and reuse the answer with confidence. Generic blog posts often bury those signals, which makes them harder for AI systems to interpret and surface.
Generic blog posts fail in AI search not because the topic is wrong, but because the structure makes the useful parts too hard to find.
The 68% filter means a large portion of a standard page never reaches the model context that shapes the final answer.
Front-load the page so the opening contains the answer, summary, and comparison logic.
Pages with clarity, section structure, Q&A formatting, and E-E-A-T signals correlate most strongly with AI citations.
The goal is not just to rank. It is to survive retrieval, ground the answer, and shape synthesis before the model moves on.
Criteria | Generic blog post | Citation-engineered page |
Opening | Scene-setting intro | Direct answer |
Main goal | Explain a topic | Be easy to extract, understand and cite |
Structure | Often loosely organised | Well structured for clarity and reuse |
Entity clarity | Often vague | Clear named entities and systems |
Paragraph style | Long and mixed | Short, focused and easily understood |
Evidence | Broad claims | Specific sources and proof |
Technical structure | Minimal structural support | Built with schema and structural signals that help LLMs digest the page |
AI outcome | Harder to reuse | Easier to retrieve, interpret and lift into an answer |
If you build the page as a citation-engineered page, then the core answer becomes easier for AI systems and buyers to understand, retrieve and reuse.
If you publish the same topic as a generic blog post, then the value may still be there, but it is more likely to be buried inside a structure that is harder to process.
Consensus Block
The Academic Proof: The GEO paper formalises generative visibility as a distinct optimisation problem, proving that structuring content for AI yields visibility gains of up to 40%.
The Platform Baseline: Google’s guidance states there are no secret, back-end technical requirements to appear in AI Overviews. Success hinges entirely on helpful, reliable, people-first content. But, for an AI to recognise your content as helpful, the answers cannot be buried.
The Industry Data: Industry study bridges the gap between the two, proving that Google's "helpful" baseline translates to practical SEO tactics: clear answers, stronger section structure, Q&A formatting, and visible expertise signals directly correlate with higher citation frequency.
What changes when AI becomes the reader
Traditional SEO is mostly about getting found and winning the click. GEO adds another test before the click even happens. The system has to decide whether your page contains a passage it can extract, trust and combine into an answer. That means a page can still rank and yet fail to appear in AI-generated responses if the best information is buried too low or written too loosely.
It is no longer enough for a page to be relevant. It also needs to be reusable.
There is no secret checklist for AI search. The best practices for SEO remain relevant for AI features and there are no extra technical requirements beyond being indexed and eligible to appear with a snippet in Search.
Answer-first structure also matters more in this environment. Google’s AI search experiences can use query fan-out to explore subtopics and sources before building a response, which means pages are more likely to contribute when the answer is clear early rather than buried deep in the page. In practice, that makes answer-first content easier for AI systems to interpret, extract and reuse. Google’s broader guidance reinforces the same principle: create helpful, reliable, people-first content that is easy to understand.
Why Generic Blog Posts Fail the AI Filter
Generic blog posts fail the AI filter because they bury the answer, leave the subject vague, and mix too many jobs into one passage. It follows a familiar sequence: open gently, set context, define the topic, introduce sub-points, then finally arrive at the answer. That reading order works for humans who choose to stay on the page. It is a weak fit for generative search because AI systems do not consume every part of the page equally. They process content in isolated chunks, and only the most accessible, explicitly structured layer survives retrieval.
Intelligent Resourcing frames this as the 68% filter. The idea aligns with Retrieval-Augmented Generation, or RAG, where an AI system retrieves relevant information from external sources before generating a response. In that process, only the parts of a page that are easy to retrieve, interpret and bring into context are likely to shape the final answer. If important information is buried too deep or structured too loosely, it may never meaningfully reach the model context, no matter how strong the content is.
Generic blog posts fail this filter in three consistent ways.
They start too slowly. Padded introductions and scene-setting bury the core answer deep on the page. AI systems require immediate, strict structure to interpret content. If the answer isn't front-loaded, it gets filtered out before it can be cited.
They are too vague. Relying on loose phrases like "this strategy" strips away context when the AI engine breaks the text down into isolated RAG chunks. An AI cannot cite what it cannot understand out of context. Semrush data shows clarity is the top citation driver, so chunks that cannot stand completely on their own are discarded.
They mix too many purposes. Trying to define, sell, and opine all in a single paragraph dilutes the core facts with marketing fluff. AI models skip messy, multi-purpose text. While some highly promotional pages do get cited, it's strictly due to flawless professional formatting, so if your page is both fluffy and poorly structured, it fails the filter entirely.
What the 68% Filter Actually Means
The 68% filter is a content engineering problem with documented technical roots. It means that much of a loosely structured page may never meaningfully influence the final answer because retrieval systems prioritise only the clearest, most accessible passages.
When a page is written in a generic, descriptive, meandering style, the most valuable parts are often the least accessible to AI systems. Important details sit too low. Comparison logic is scattered. The commercial implication appears at the end. The article may contain the right ideas, but they are structurally hard to extract.
This is also where old terminology starts to break down. Answer Engine Optimisation (AEO) helped marketers think about answer-first formatting. That was a useful shift. But Generative Engine Optimisation (GEO) is the more accurate frame now. As recent academic research confirms, generative AI requires multi-document synthesis. The real problem is no longer simply answering the query. It is surviving retrieval, grounding the answer with explicit proof, and shaping synthesis before the model moves on.
That leads to four kinds of loss:
Answer loss happens when the core takeaway appears too late. This triggers a documented LLM flaw known as the "Lost in the Middle" phenomenon, where models fail to extract information buried deep in the text.
Context loss happens when the page assumes the model will infer the system from broad topic language rather than explicitly named entities.
Decision loss happens when the article describes a topic but never helps the model choose between options. Without clear structural comparisons, the AI's burden to synthesise an answer is too high.
Proof loss happens when the strongest causal logic or evidence sits below the opening sections, meaning the RAG system filters it out before synthesis even begins.
This is the hidden failure mode of content in the AI era. Teams assume the issue is quality, originality, or authority alone. Those matter, but they are not enough. The first question is more basic: did the most important parts of the page survive long enough to influence synthesis?
If the answer is no, the page has already failed.
The Trinity Framework
The Trinity Framework makes content easier to cite. Every important section should answer three questions:
Who or what is doing the work?
What action happens?
What risk is avoided?
This is what turns a broad article into a citation-engineered page.
1) Who or what is doing the work?
Start by naming the thing clearly. That could be a framework, a workflow, a service page, a pricing page, or a schema layer. Do not make the reader or the model guess. “This method” is weaker than “the Trinity Framework”. “This page type” is weaker than “a citation-engineered service page”.
Clear naming matters because AI systems often work with smaller passages rather than the full narrative of the page. If the subject is vague, the passage becomes weaker the moment it is lifted out of context. That is one reason clarity and section structure correlate with citation visibility.
Weak version: This strategy helps brands show up more often.
Better version: The Trinity Framework helps B2B brands structure pages for AI citation.
The second sentence is easier to extract because it names the framework, the audience and the outcome in one go.
2) What action happens?
Once the subject is clear, explain what it actually does. This is where many weak blog posts stay too abstract. They say something matters without explaining the mechanism.
Strong sections use direct verbs such as define, compare, connect, verify, extract and cite. They tell the reader what happens on the page and why the structure is useful.
Weak version: Schema improves AI readiness.
Better version: Structured data helps search systems understand the page, while the on-page answer block gives the model a clean passage to extract.
The second version is more useful because it explains the action, not just the label.
3) What risk is avoided?
This is the part most generic content misses. A citable section should explain what goes wrong when the advice is ignored. Risk makes the advice sharper. It also makes the content more decision-ready.
Google’s structured data guidance is helpful here because it is very explicit. Structured data is not guaranteed to appear even when valid. It may be ignored if it is not representative of the main content, if it is misleading, or if it describes content hidden from readers. Google also says structured data pages should not be blocked from Googlebot with robots.txt, no index or other access controls.
Weak version: Use structured data for better understanding.
Better version: Use structured data that matches the visible page, otherwise it may become misleading or less useful.
That final line tells the reader why the rule matters.
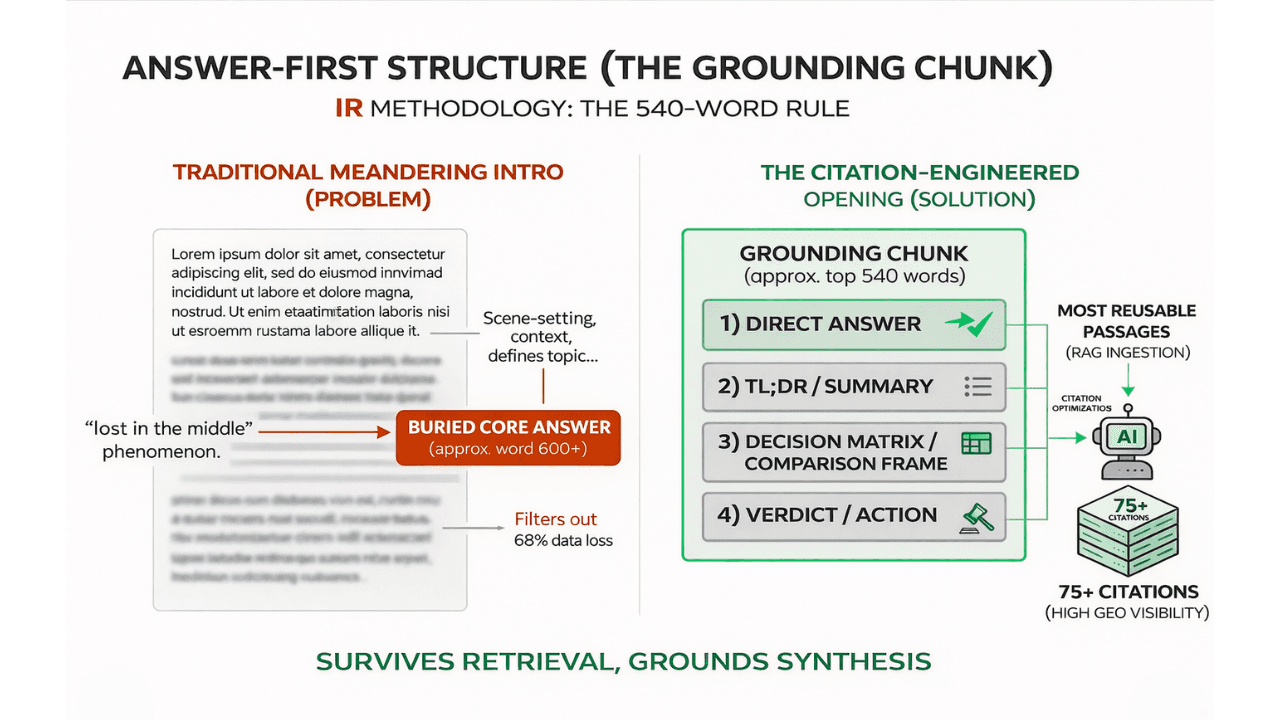
The 540-word Grounding Chunk rule
At Intelligent Resourcing, the practical rule is simple: treat the opening section as the part of the page most likely to do the heavy lifting. Put the direct answer, the short summary, the decision logic and the verdict at the top.
This is not a rule about writing short articles. It is a rule about writing useful openings. Long-form content can still work very well, but only when the first section already contains something worth extracting.
That is why this article starts with the answer, then the TL;DR, then the comparison logic, then the verdict. The opening should not be a warm-up. It should be the most reusable part of the page.
A simple formula works well:
a direct answer
a short TL;DR
a comparison or decision frame
a verdict
a clean transition into explanation
Structure belongs in the build stage, not as a final tidy-up pass.
What a citation-engineered page looks like in practice
A citation-engineered page is easy to skim and easy for an AI to lift. It never hides the core answer. Instead, it relies on short paragraphs, clear headings and explicitly defined entities to ensure every section makes sense on its own.
The Standalone Extraction Test To verify if your content is citation-engineered, apply the extraction test to your core sections:
Question: Would this single paragraph still make complete sense if an AI pulled it out and displayed it entirely on its own?
Rule: If the answer is no, the section needs to be rewritten.
Structure comes before markup, but not instead of it
Structure is the first layer. Markup is the reinforcement layer. Once the visible page is clear, schema markup for AI citation can help search systems understand what the page is about and classify the content more explicitly. Google’s structured data documentation says structured data gives explicit clues about the meaning of a page and classifies the page content, but it also says the markup should describe the content of that page and should not be added for information that is not visible to the user.
That distinction matters because markup cannot rescue a vague page. Even correctly implemented structured data is not guaranteed to appear as a feature in search, and Google says eligibility depends on multiple factors. So the page still has to do the primary work clearly in plain sight.
The same logic applies to crawler access. OpenAI’s crawler documentation says site owners can manage OAI-SearchBot and GPTBot using separate robots.txt tags. That means AI visibility is partly a content issue and partly an access issue. Good structure helps. So does making the right content available to the right systems. This is also where LLM SEO becomes useful as the wider architecture layer around the page itself.
Common failure modes to remove before publishing
The fastest way to improve AI citation potential is often subtraction.
Long soft introductions that delay the real answer
Unnamed entities and vague pronouns
Paragraphs trying to do too many jobs at once
Promotional claims without named proof
Structured data that does not match the visible page
Important content hidden behind weak section openings
Each of these issues reduces extractability, weakens citation confidence, or hides the answer too late.
These are not small editorial issues anymore. In AI search, they become retrieval issues. That is why this article should work as a proof page, not just a general explainer.
The practical takeaway for B2B teams
If your page has to choose between sounding expansive and being easy to extract, choose extractability first. You can always add depth afterwards. What you cannot rely on is an AI system cleaning up a buried answer, fixing your entity clarity, or rebuilding your section logic for you.
That is why citation engineering is really a page design problem before it becomes a traffic problem. A strong page says the important thing early, explains how it works, and removes ambiguity before the section is ever reused somewhere else. That is the practical logic behind The GEO Engine.
FAQs
What is citation-engineered content?
Citation-engineered content is content designed to be easy for AI systems to extract, interpret and reuse. It usually leads with a direct answer, uses clear structure, names entities explicitly and supports claims with credible evidence. The overall direction is consistent with both the GEO paper and Semrush’s recent citation study.
Is this the same as SEO?
Not exactly. Traditional SEO focuses on visibility in ranked results. GEO adds visibility inside AI-generated answers. The two overlap, but they are not identical. Google’s own guidance says existing SEO best practices still apply for AI features, while the GEO paper frames visibility in generative engines as a distinct optimisation problem.
Does longer content always perform better?
No. Depth can help, but only when the best information is easy to find and easy to reuse. Semrush’s January 2026 study points more strongly to clarity, summarisation, structure and expertise signals than to simple length.
Is structure more important than schema?
Structure comes first. Schema helps reinforce meaning, but it cannot rescue a vague page. Google’s structured data documentation makes that clear by requiring the markup to reflect the page and visible content accurately.
Can a page rank in Google and still fail in AI answers?
Yes. A page can be relevant enough to rank and still fail to provide the clean, reusable passages that generative systems prefer. That is one of the core reasons GEO has emerged as a separate optimisation lens.
Conclusion
The challenge is not only getting a page discovered. It is making sure the most important parts are easy for AI systems to retrieve, interpret and reuse.
That is where citation-engineered pages matter. They are structured to make the core answer clear early, supported with evidence and easier to carry into AI-generated responses.
If the meaning is buried or loosely organised, the page may still be relevant, but it becomes far less reusable.