Schema Markup for AI Citation
Every page without grounding-layer schema is harder for AI to cite. Use the Schema Parity Rule, Problem-Space Protocol, and 7-point checklist to fix it.
By Ronan Leonard, Founder, Intelligent Resourcing

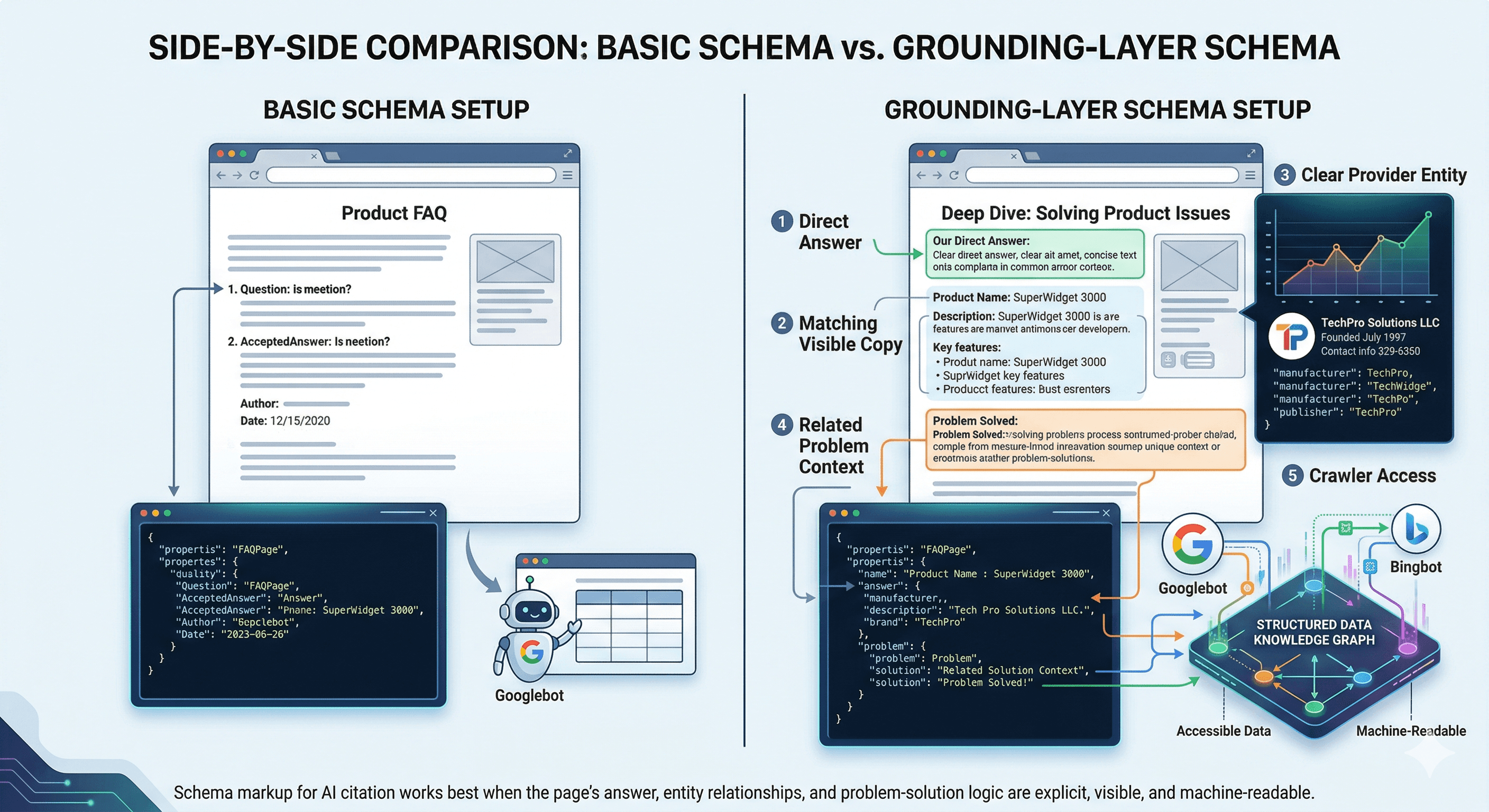
Grounding-layer schema helps pages earn AI citations by making the page’s answer, entities, and problem-solution logic explicit in machine-readable form. Standard SEO schema helps classify a page. A grounding-layer approach makes the most important meaning clearer, more consistent, and easier to interpret across search and AI systems.
Standard schema helps search systems understand and classify page content, but it does not guarantee visibility on its own.
For AI citation, the markup should match the visible page exactly. If the machine-readable layer says one thing and the page says another, trust drops.
Google recommends JSON-LD because it is easier to implement and maintain, which usually makes it the cleanest format for a grounding layer.
Schema helps most when it is paired with clear on-page structure, crawl access, and consistent entities. It reinforces meaning. It does not rescue a weak page.
Criteria | Standard schema setup | Grounding-layer schema setup |
Main purpose | Classify page content | Clarify the answer and relationships |
Focus | Eligibility and enhancement | Meaning, parity, and machine trust |
Answer handling | Often generic or absent | Direct answer mirrored clearly |
Entity logic | Basic | Linked service, provider, and context |
Risk control | Limited | Built around consistency and visibility |
Best use | General SEO support | GEO and AI citation readiness |
If you build a grounding-layer schema that mirrors the page, names the entity clearly, and connects the service to the problem it solves, then AI systems can interpret, trust, and cite your page with confidence.
If you treat schema as a bolt-on or rely on vague markup that does not match the visible page, then even a well-written page becomes harder for AI systems to read, trust, and reuse.
Consensus Block
The Platform Baseline (Google): Google explicitly states there are no special schema tags or extra technical requirements needed to appear in AI Overviews. Structured data’s role is simply to provide explicit clues about a page’s meaning, and it must strictly reflect what users can actually see.
The Vocabulary Layer (Schema.org): Schema.org provides the established relationship vocabulary required to connect services, entities, and actions. You do not need new code; you just need to use the existing code to map logical relationships clearly.
The Access Layer (OpenAI): OpenAI’s documentation confirms that technical access is a distinct part of the puzzle. Search visibility (via
OAI-SearchBot) and training permissions (viaGPTBot) are controlled independently, meaning AI visibility requires intentional crawler management.
Put together, this points to a highly practical conclusion for B2B teams: the best schema for AI citation is clear, accurate, visible, connected, and explicitly crawlable.
Why standard schema is not enough anymore
Standard schema is often treated as a rich-results task. A team adds Article, FAQ, Organisation, or Service markup, validates it, and assumes the job is done. That is fine as a baseline, but it is not enough for pages that need to support AI citation. Google is clear that structured data can enable certain features, but it does not guarantee that those features will appear, and rich-result eligibility is only one part of the picture.
The bigger issue is that standard implementations are often too shallow. They label the page type, but they do not make the core answer or the service logic especially clear. That matters more now because AI systems need usable meaning, not just a valid object type. Google’s AI features documentation reinforces the same idea from another angle: there are no extra technical requirements for AI Overviews or AI Mode, but the page still needs to be indexed, snippet-eligible, and built on solid SEO fundamentals.
So schema should not be treated as decoration. It should be treated as part of the page’s grounding layer.
What the grounding layer actually does
A grounding layer is the machine-readable version of the page’s core meaning. It tells systems what the page is about, who the main entity is, what service is being offered, and how key elements connect. Google describes structured data as explicit clues about the meaning of a page and as a standardised format for classifying page content. That is exactly why it matters beyond rich snippets.
In practice, the grounding layer works best when it strictly mirrors the page’s main answer. The markup should make the text easier for an AI to interpret, not introduce a second version of the truth. Google’s guidelines are direct: structured data must accurately represent the visible page and never mark up hidden or misleading content. Because there is no "special" schema required to appear in AI features, the visible text must do the heavy lifting in plain sight first. The schema simply reinforces that work.
The Schema Parity rule
The simplest rule in this article is also the most important: the schema should say the same thing as the page.
If your visible answer says one thing and your machine-readable answer says another, the page becomes harder to trust. Even when the markup is technically valid, that mismatch creates ambiguity. Google’s guidance backs this up in plain language. It says not to mark up content that is not visible to readers, not to add irrelevant or misleading markup, and to ensure that structured data is a true representation of the page content. It also specifically recommends making sure structured data matches the visible text on the page for AI features.
For B2B service pages, that means the direct answer, service summary, and main entity naming should stay aligned across the page title, opening section, and JSON-LD. Small wording differences are fine when the meaning is identical. Meaning drift is the real problem.
A simple example makes the point.
Weak parity
Visible page: “We help B2B brands improve visibility in AI search.”
Schema description: “We are a full-service digital growth consultancy for all modern search channels.”
Strong parity
Visible page: “We help B2B brands improve visibility in AI search.”
Schema description: “Generative Engine Optimisation services that help B2B brands improve visibility in AI search.”
The second version is not cleverer. It is just clearer.
The Problem-Space Protocol
Many service pages mark up the service, but stop there. They define the offer without defining the problem it solves. That leaves the machine with an incomplete map.
Schema.org gives you a better option. On Service, you can use properties such as provider, sameAs, potentialAction, and isRelatedTo to make the entity and its relationships clearer. potentialAction describes an idealised action in which the thing plays an object role, while sameAs points to a reference page that unambiguously identifies the entity. isRelatedTo can also connect a service to another related product or service.
In practice, this means a service page should do more than say “this is our GEO service.” It should also help a machine understand the wider problem space: AI visibility, citation readiness, structured content, entity trust, or answer extraction. That is the point of the Problem-Space Protocol. It gives the markup more context, so the service is not floating on its own.
The service page is the parent commercial asset within The GEO Engine. This article is the proof layer that explains how one part of that engine works.
JSON-LD vs rendered HTML
The safest public position is not that all LLMs read JSON-LD first or prefer it over rendered HTML in every case. The stronger and better-supported point is that JSON-LD gives search systems a cleaner, explicit meaning layer, and Google recommends it because it is easier to implement and maintain at scale. Google also notes that JSON-LD is not interleaved with visible text, makes nested data easier to express, and can be read even when injected dynamically.
That matters in the real world because rendered pages are often messy. Navigation, tabs, scripts, repeated components, and boilerplate can make the visible document noisy. JSON-LD does not replace the visible page, but it can provide a cleaner summary of what the main entity and key relationships are.
So the practical conclusion is simple. Use JSON-LD because it is the clearest supported format, not because you assume it bypasses the page. Google’s own guidance says all supported formats are acceptable when properly implemented, but JSON-LD is usually the easiest to maintain and least prone to implementation errors.
Common schema mistakes that weaken AI citation
The most common mistake is thinking valid markup is enough. It is not.
A page can have syntactically correct schema and still be weak because the markup is too generic, the entity names are inconsistent, or the visible copy does not match the structured data. Google’s guidelines warn that violating quality rules can stop correct markup from being shown as a rich result, and that structured data can even trigger manual actions if it becomes misleading.
Another common mistake is marking up content that users cannot actually see. Google explicitly says not to mark up content that is not visible to readers of the page. That matters for hidden tabs, accordions, and technical answer blocks. If you use them, the content still needs to be genuinely present and accessible on the page, not invented for markup alone.
There is also a strategic mistake around FAQ markup. Some teams still treat FAQPage as a broad shortcut to extra visibility. That is out of date. Google’s current FAQ documentation says FAQ rich results are for government-focused or health-focused sites, and Google’s 2023 update said FAQ rich results would only be shown regularly for well-known, authoritative government and health websites. For most B2B brands, FAQ schema may still help organise content, but it should not be sold internally as a general rich-result tactic.
Grounding layer checklist for B2B service pages
A good B2B service page does not need dozens of schema objects. It needs a clean, believable set of signals.
One clear answer on the page. The core response is visible and easy to find.
One matching answer in the schema layer. The markup reflects what the page actually says.
One consistent service name. The same terminology is used across the page, title, and JSON-LD.
One clearly identified provider. The entity behind the service is explicitly named.
One usable relationship layer for context. The service is connected to the problem it solves.
One crawlable, indexable page. The right systems can access and read the content.
One set of visible proof signals. Expertise and credibility are evident on the page itself.
The page structure comes first.The schema layer sharpens it afterwards
Why schema still needs access, structure, and trust
Schema only works when three things line up: the page is accessible, the page is clearly structured, and the page is trustworthy enough to reuse.
Google says pages shown as supporting links in AI features must still be indexed and eligible to appear with a snippet. Google also says structured-data pages should not be blocked from Googlebot. That means markup cannot help much if the page is inaccessible or badly surfaced.
OpenAI’s crawler documentation adds another important layer. OAI-SearchBot and GPTBot are controlled independently in robots.txt, which means search visibility and training permissions are separate choices. Good schema helps, but it still depends on the right content being available to the right systems.
So the logic is simple. Structure comes first. Access makes that structure reachable. Trust makes it reusable. Schema strengthens all three, but it does not rescue a vague page.
Teams looking at schema usually need to think about crawler and access policy next.
The practical takeaway for B2B teams
Do not ask whether you have a schema. Ask whether your schema helps a machine understand the page faster and more accurately.
That is the shift from standard markup to grounding-layer markup. The goal is not to generate more code. The goal is to reduce ambiguity. When the visible answer, entity logic, and machine-readable layer all point in the same direction, the page becomes easier to classify, easier to trust, and easier to reuse.
FAQs
What is schema markup for AI citation?
It is the use of structured data to make a page’s meaning, entities, and relationships clearer for machine interpretation. The strongest implementations mirror visible copy and help reinforce the page’s main answer rather than adding disconnected metadata.
Is JSON-LD better than Microdata for GEO?
Google supports JSON-LD, Microdata, and RDFa, but recommends JSON-LD in most cases because it is easier to implement and maintain. That makes it the practical default for most GEO work.
Does the schema need to match the visible copy exactly?
The safest rule is yes in meaning, and as closely as possible in wording. Google says structured data should reflect visible content, should not mark up hidden content, and should not be misleading. Google’s AI features guidance also says structured data should match the visible text on the page.
Can FAQ schema still help if it does not generate rich results?
It can still help you organise question-and-answer content on the page, but most commercial sites should not expect regular FAQ rich results. Google’s current documentation restricts that treatment to government-focused and health-focused sites.
What schema properties help connect a service to a problem?
For service pages, properties such as provider, sameAs, potentialAction, and isRelatedTo can help define the service entity and its context more clearly. Whether each one is appropriate depends on the page and the relationship being described.
Conclusion
Do not build schema as a bolt-on. Build it as part of the page’s meaning layer.
That is the key distinction between standard schema and grounding-layer schema. If the markup only labels the page, it may still be useful. But if it also mirrors the direct answer, reinforces the right entities, connects the service to the problem space, and stays accessible to crawlers, it becomes far more valuable for GEO.
The practical lesson is simple. Better schema is not about adding more code. It is about reducing ambiguity so the page becomes easier to interpret, easier to trust, and easier to cite.