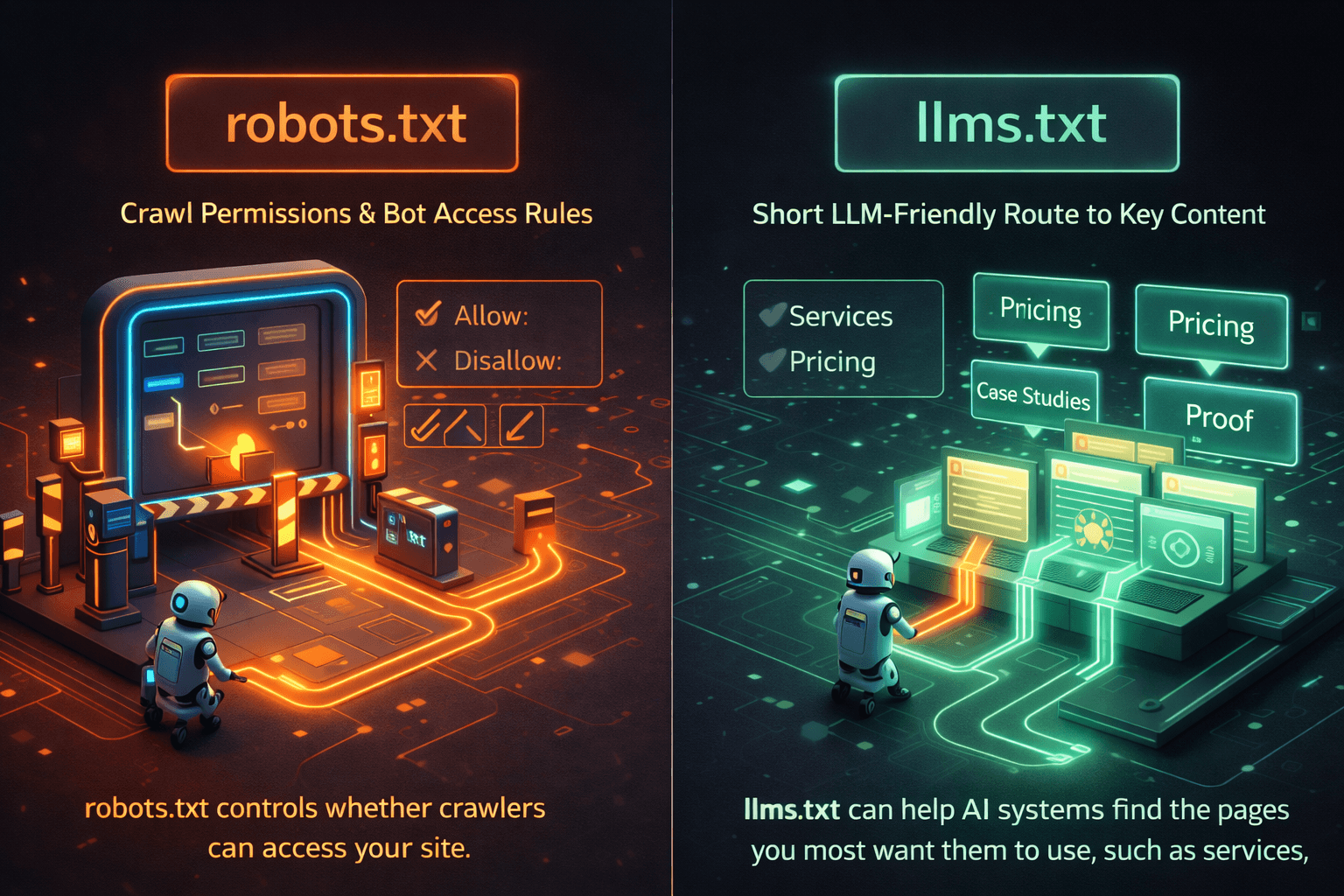
Robots.txt vs llms.txt: How to Give AI Crawlers a Direct Path to Your Best Content
Most B2B sites are crawlable but not citable. robots.txt controls access. llms.txt helps route AI to the pages you most want cited. Here is how to set it up.
By Ronan Leonard, Founder, Intelligent Resourcing

robots.txt controls access. llms.txt helps AI systems find the pages you most want them to use, such as services, pricing and case studies. It does not replace crawler controls. It works best as a routing layer on top of access controls, strong page structure and clear schema.
Use robots.txt to grant AI crawler access and llms.txt to route them to high-value pages for better AI citation rates
Curate llms.txt with services, pricing, case studies and proof content to increase extraction accuracy by focusing AI on commercial pages
Structure pages with clear headings and schema markup to enable AI systems to extract and cite your content correctly
Keep your priority list selective, not exhaustive by including foundational commercial and proof pages to avoid routing AI to weak or irrelevant content
Treat the priority file as a maintained layer and review it when offers, pricing or case studies change to prevent it from becoming a liability instead of a shortcut
Criteria | robots.txt | llms.txt |
Main job | Controls crawler access | Supports page routing |
Format | Crawl directive file | LLM-friendly text or markdown file |
Best use | Allow or block bots | Surface priority pages |
Replaces the other? | No | No |
Ideal for | Access controls and crawl hygiene | Services, pricing, case studies and proof pages |
Risk if used alone | Access without direction | Direction without access |
If you deploy the llms.txt protocol to actively map out your citation engineered pages, then you are not just letting AI crawl your site, you are handing the model a curated, high-priority shortcut directly to your most valuable answers before they get buried in site noise.
If you rely purely on traditional robots.txt to manage AI crawlers, then you are only telling the system what it cannot read, leaving the model to blindly guess which of your allowed pages actually matter.
Robots.txt vs llms.txt
The simplest way to understand the difference is this: one file opens or closes the door, the other shows the best route once the door is open.
Google defines robots.txt very clearly. It tells crawlers which URLs they can access on your site, and it is mainly used to manage crawler traffic. It can allow or block crawling, but it does not tell an AI system which pages are most useful, most current or most worth summarising.
That is where the routing layer becomes useful. The proposal describes it as an LLM-friendly markdown file that gives background, guidance and links to more detailed markdown pages. In practice, that makes it less like a gate and more like a curated menu.
What this routing layer actually is
llms.txt is best understood as a routing file or a routing layer for AI use, not as a new version of robots.txt
The proposal exists because modern websites are noisy. Navigation, JavaScript, sidebars and repeated interface elements are useful for people but inefficient for language models. The file helps reduce that noise by pointing systems to the pages that explain your business fastest and most clearly.
For a B2B brand, that usually means:
Service pages that explain what you do
Pricing pages that show commercial intent
Case studies that provide proof
Core definition pages that explain your method or framework
High-value support articles that clarify technical concepts
It works best as part of a wider GEO setup rather than a standalone fix. It fits naturally into The GEO Engine, supporting the Audit and Build phases by reducing friction between crawler access and useful page discovery.
Why AI crawlers need a direct path
AI crawlers need a direct path because many of the answers that matter most are buried under navigation, templates, repeated modules and low-value pages. AI systems do not read websites the way a patient human reader does, so a page can be crawlable without being easy to interpret or prioritise.
That is why the proposal argues for a cleaner entry point. Documentation teams at OpenAI, Anthropic and Cloudflare already publish machine-friendly paths to core content.
OpenAI publishes both
llms.txtandllms-full.txtviews of its docs.Anthropic includes a specific "Resources for AI ingestion" section built on the exact same protocol.
Cloudflare links each product to its own file, recommending it as the best way for AI to explore product content.
This does not prove that every AI crawler reads it, but it does show that leading platforms see value in compact, noise-free content paths.
For B2B sites, the most important pages are rarely the homepage or the latest blog post. They are usually the pages closest to decision-making: services, pricing, implementation details and proof.
What to Include and Exclude in your routing file
What to Include
For most B2B brands, the strongest inclusions should be grouped to make your site's hierarchy explicitly clear to the crawler:
Entity Pages (Who you are): About or entity pages if they clearly define the company's identity and market position.
Commercial Pages (What you do): Core service pages that define the offer, alongside specific pricing or package pages.
Proof Pages (Why you are trusted): Case studies with real, measurable outcomes, plus technical proof architecture (such as your guides on schema markup for AI citation and structuring content for AI citation).
The Golden Rule: If a page helps a model clearly answer, "What does this company do, how does it work, what proof exists, and where do I go next?", it is a strong candidate.
What NOT to Include (The Noise)
The easiest way to weaken the routing file is to make it too broad. Do not fill it with:
Every blog post: Only include foundational, high-proof pillar pieces.
Thin architecture: Category pages, tag archives, and duplicate pages targeting the same intent.
Blocked content: Pages already blocked (this creates conflicting access signals).
Fluff: Weak promotional pages with little substance or outdated URLs.
How to set up this routing layer
Place the file at the root of the site as /llms.txt. Keep it in plain text or markdown. Group links by business purpose if that improves readability. Prioritise stable URLs over campaign pages or temporary landing pages.Review it whenever your core offers, pricing structure, or proof pages change.
A practical structure might look like this:
Services
Generative Engine Optimisation
Citation audit
Content architecture
Commercial pages
Pricing
Contact
Case studies
Proof pages
Schema guide
Content structure guide
Platform-specific optimisation pages
Maintain the file. If it points to obsolete pages, it becomes a liability rather than a shortcut.
Why the routing layer does not replace crawler controls
This only works when crawler permissions are already correct.
OpenAI says OAI-SearchBot and GPTBot are managed using separate robots.txt tags, and that each setting is independent. Sites that are opted out of OAI-SearchBot will not be shown in ChatGPT search answers, though they may still appear as navigational links.
Anthropic documents the same kind of split. ClaudeBot relates to training, Claude-User is used when individuals ask Claude questions that may retrieve web content, and Claude-SearchBot navigates the web to improve search result quality. Anthropic also says disabling Claude-User may reduce visibility for user-directed web search.
That means it sits on top of crawler permissions. It does not override them.
If the bot cannot access your site, your routing layer will not fix the problem. Access comes first. Routing comes second.
Why still needs structure and schema
Even when llms.txt works perfectly, it only gets the system to the page. It does not guarantee that the page is easy to interpret.
That is where structuring content for AI citation matters. Once the crawler lands, the page still needs a clear direct answer, strong headings, defined entities, short sections, and a page structure that survives retrieval and summarisation.
Then schema markup for AI citation adds the grounding layer. It helps reinforce the meaning of the page and the relationships between the service, the organisation, and the problem being solved.
So the flow is simple:
robots.txt allows access
llms.txt points to the right pages
page structure makes the content easy to extract
schema reinforces the meaning
That is the joined-up approach most B2B brands actually need.
Common mistakes B2B teams make
Treating it as a trend, not a tool: it is not a vanity metric. It is a functional routing tool designed to make your best pages easier to find.
Routing systems to weak pages: if your service pages are vague and your case studies are thin, the priority file simply helps crawlers reach bad content faster.
Ignoring crawler access: Guidance without access fails. OpenAI and Anthropic bots still require permissions to read the pages you point them to.
Letting the file go stale: Business priorities change. If you do not update the file when new pricing or case studies go live, it can misdirect AI.
The practical takeaway for B2B teams
Do not ask whether routing layer is a universal standard yet. Ask a more useful question: would an AI system reach your best pages faster if you gave it a cleaner map?
For many B2B sites, especially those with buried service and proof pages, the answer is yes.
It reduces friction between crawler access and your most commercial, explanatory, and evidential pages. It is not a replacement for robots.txt. It works best as a routing layer on top of a well-structured site.
FAQs
Does llms.txt replace robots.txt?
No. robots.txt controls crawler access. It supports page routing. The two files do different jobs.
What pages should go in the routing file?
The best candidates are the pages that explain your business fastest and most clearly, usually services, pricing, case studies and high-value proof pages. Treat it as a curated shortlist, not a full sitemap.
How do I route AI to priority pages?
Place a plain text priority file at your site root. Group links by business purpose: services, commercial pages and proof pages. Prioritise stable URLs over campaign or temporary pages. Review it whenever core offers, pricing or proof pages change to avoid routing AI to obsolete content.
Do ChatGPT and Claude still use robots.txt rules?
Yes. OpenAI documents separate robots.txt controls for OAI-SearchBot and GPTBot, and Anthropic documents ClaudeBot, Claude-User, and Claude-SearchBot with separate effects on training and user-directed retrieval.
Conclusion
robots.txt tells bots where they can go. llms.txt helps show them where to start.
That is still the clearest way to think about it. For B2B teams, the real value is not publishing a new file for the sake of novelty. It is using routing layer to guide AI systems towards the pages that explain your services, prove your value and move buyers closer to action.