How to Get Cited by AI Search Engines in 2026
95.7% of B2B brands are absent from AI discovery. Here is how ChatGPT, Perplexity, Gemini and Copilot each select sources and what to build to get cited.
By Ronan Leonard, Founder, Intelligent Resourcing

Getting cited by AI search engines requires direct-answer content, verified entity signals and AI-crawlable technical architecture. ChatGPT, Perplexity, Gemini and Copilot each weigh these signals differently. Definitive content achieves a 36.2% citation rate versus 20.2% for hedged content, a 79% performance gap that holds across all 4 major engines.
95.7% of B2B brands are absent from AI discovery: The 2X AI Visibility Index found only 4.3% of companies appear in early-stage AI queries, before buyers form a shortlist.
Each engine uses a different retrieval mechanism: ChatGPT draws from training data and live retrieval. Perplexity runs a 3-layer machine learning reranker with live web access. Google AI Overviews pull 62.9% of citations from outside the top-10 search rankings.
The shared baseline is direct answers: all engines reward content that answers a complete question in under 400 words, with named entities, a verifiable claim and no hedged language.
Content format outranks domain authority: FAQ schema achieves 2.7x higher citation rates. Question-format H2s earn an 18% citation rate.
Signal | ChatGPT | Perplexity | Gemini / AI Overviews | Copilot | Grok |
Retrieval Method | Training corpus + live RAG retrieval | Live web via Bing index and IndexNow | Google index + training | Bing index | X/Twitter signals + Bing web |
Citation Trigger | Entity recognition in training corpus | 3-layer ML reranker: BM25 + cross-encoder + domain authority, recency and entity signals | Top-10 correlation (37.1% of cites); 62.9% from outside top-10 | Structured content + Bing authority | Recency + social proof + verifiable entities |
Schema Impact | Moderate | Low | High: JSON-LD mapped to AI Overview extraction | Moderate | Low |
Recency Weighting | Low–moderate | High | Moderate | High | Very high |
Best Content Format | Q&A blocks with named entities | Fresh structured content with authority signals | FAQ schema + entity markup | Crawlable Q&A with consistent schema | Recent original claims with verifiable sourcing |
When Traditional SEO Still Wins | High-volume informational keywords following blue-link pattern | Competitor brand queries where buyers already have a name | Local, map-pack and navigational intent | Direct URL navigation and brand queries | Breaking-news queries where social timing beats depth |
Traditional SEO still wins for high-volume keywords and brand searches. But B2B brands that want to be cited by ChatGPT, Perplexity, Gemini, Copilot and Grok need a full citation architecture: entity signals, answer-first content, schema, verified proof and crawlable technical foundations. Intelligent Resourcing AEO/GEO service installs these foundations so you are visible in AI Answer.
Why Are 95.7% of B2B Brands Absent From AI Discovery?
95.7% of B2B brands are absent from AI discovery because their pages are built for keyword rankings, not for AI extraction. AI language models require 200 to 400-word passages that answer a complete buyer question without surrounding context. Most B2B content is structured for human reading, not machine passage extraction. The gap is architectural, not a content volume problem.
The 2X AI Visibility Index analysed 70 B2B companies and found that only 4.3% appeared in early-stage buyer questions. The remaining 95.7% appeared primarily in queries where buyers already knew the company name.
The problem is structural because most B2B websites are built for SEO: keyword-dense pages, heading structures that describe services rather than answer questions, and brand language that assumes the reader already recognises the company.
AI language models do not read pages the way humans do. They extract answer units: 200 to 400-word passages that answer a specific question completely without requiring the reader to infer meaning from surrounding context. If the page does not contain a passage that matches a buyer query with a direct, verifiable answer, the engine skips it.
The DerivateX AI Visibility Study ran 1,400 buyer-intent prompts across ChatGPT, Perplexity, Claude and Gemini for 50 B2B SaaS companies. The average AI Presence Score was 56.9 out of 100. 44% scored below 50.
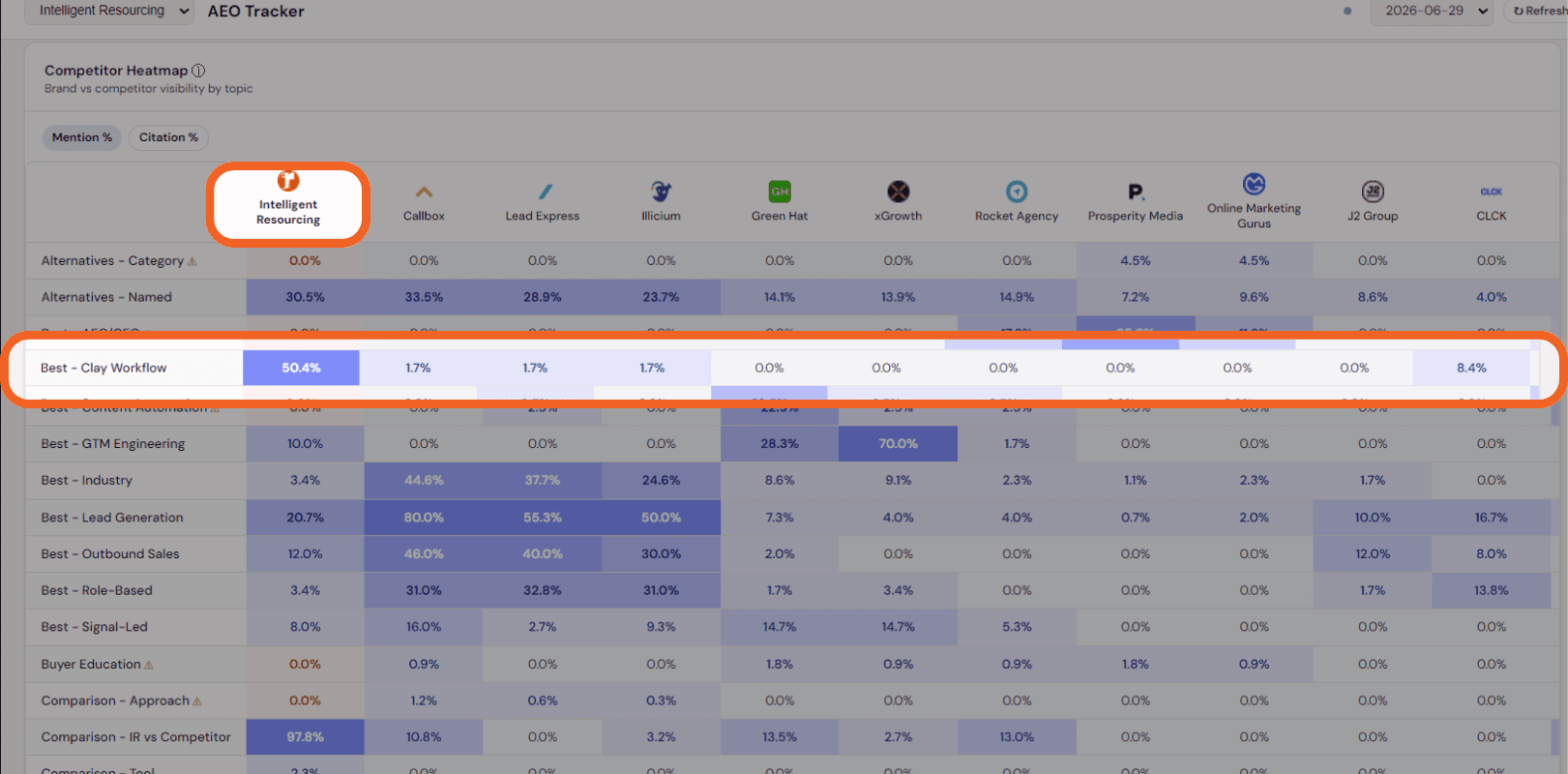
Intelligent Resourcing's own June 29, 2026 AEO tracker data confirms the gap exists inside a built citation programme. In the Best Clay workflow cluster, Intelligent Resourcing holds a 50.4%mention rate higher against the other competitor. Buyers asking AI engines to recommend clay work flows in Australia receive a shortlist that include Intelligent Resourcing. That is the commercial cost of a built content cluster.
The fix starts with understanding how each engine selects sources. The buying signal layer, being cited when a specific account is in-market, requires the content architecture to be in place first. A brand absent from general category answers will also be absent when a named account triggers a buying signal.
What Signals Do All AI Engines Share?
All major AI engines share 4 citation signals: entity clarity, direct-answer structure, source consistency and definitive language. All 4 must be present on the same page. No single signal substitutes for the others. A page with strong entity signals but hedged language will underperform a page that satisfies all 4 criteria at once.
Entity Clarity
Every page must use the same company name, service category, location and key descriptors. If the homepage says "Intelligent Resourcing," the blog says "IR" and a partner directory says "IR Agency," the AI system cannot resolve these to the same entity. Intelligent Resourcing's GEO Answer-First Page Framework found that AI-cited content averages 20.6% entity density, measured as the share of words that are named entities, versus 5 to 8% for typical web content. Pages below the entity threshold are extracted less frequently regardless of domain authority.
Direct-Answer Structure
The page must contain a passage that answers a complete question in under 400 words without requiring the reader to piece together the answer from surrounding paragraphs. FAQ sections and question-format H2 headings outperform statement headers because the extraction model finds pre-structured question-answer pairs before it reads general prose.
Source Consistency
The same factual claims, dates and proof points must appear across all pages without contradiction. AI systems that encounter conflicting information about the same brand on different pages reduce that brand's citation probability.
Definitive Language
Intelligent Resourcing's GEO Framework found definitive content achieves a 36.2% citation rate versus 20.2% for hedged content. Pages with explicit external citations receive +115% AI visibility versus uncited pages making the same claims. The penalty for hedged language holds across ChatGPT, Perplexity, Gemini and Copilot.
How Does Each AI Engine Actually Select Sources?
Each engine uses a different citation mechanism. The safest approach is to build the shared baseline first: entity clarity, answer-first structure, source consistency, crawlability and external proof. Engine-specific optimisation improves citation probability after that baseline exists. Chasing a single engine's formula produces fragile results when that engine updates its retrieval logic.
ChatGPT
Step 1: Build entity recognition
ChatGPT's answers draw from 2 sources: its training corpus and, when browsing is enabled, live retrieval via Bing. For most B2B category queries, the training corpus determines whether a brand is known at all.
Step 2: Establish public consistency
ChatGPT citation is heavily correlated with whether the brand exists as a recognisable entity across publicly indexed content: third-party mentions, industry directories, press coverage and cross-site consistency.
Step 3: Strengthen trusted profiles
Entities that appear in ChatGPT answers typically have verifiable presence on high-authority platforms prominent in the training data: LinkedIn company pages, Crunchbase, industry publication directories and Wikipedia-adjacent sources.
Step 4: Fix entity establishment first
For brands that do not appear in ChatGPT answers, the fix is entity establishment, not keyword optimisation.
Perplexity
Step 1: Get indexed quickly
Perplexity uses live web retrieval via Bing's index and the IndexNow protocol, meaning newly published content can earn citations within days of indexing.
Step 2: Match the query and meaning
Layer 1 retrieves candidate documents using BM25 keyword matching combined with semantic embedding similarity.
Step 3: Pass full-context evaluation
Layer 2 applies a cross-encoder model that evaluates query and document together in full context.
Step 4: Prove authority and freshness
Layer 3 incorporates entity-level signals, domain authority scores, recency weighting and source diversity.
Step 5: Become one of the few cited sources
Of the pages Perplexity retrieves per query, only 3 to 4 are cited in the final answer.
Step 6: Build citation-ready pages
A well-structured page on a credible domain, with clear entity signals, a direct answer block and an explicit external citation, reaches Perplexity citation status faster than on any other major engine.
Google Gemini and AI Overviews
Step 1: Clear the Google index
Google Gemini and AI Overviews share the same underlying Google index. AI Overviews is Google's direct-answer layer inside search results. Gemini is a standalone conversational product, but both benefit from the same entity and content structure work.
Step 2: Do not rely only on top-10 rankings
Ahrefs research across 863,000 SERPs and 4 million AI Overview URLs found that only 37.1% of cited pages rank in the top 10 organic results. The remaining 62.9% of cited pages rank outside position 10.
Step 3: Build structured answer content
High-quality structured content earns AI Overview citations without a top-10 ranking, provided the page passes the entity, direct-answer and technical structure requirements.
Step 4: Match schema to visible content
JSON-LD schema has a direct impact on Gemini and AI Overview performance. The Parity Rule applies: acceptedAnswer values in FAQPage schema must match the visible on-page text exactly.
Microsoft Copilot
Step 1: Optimise for Bing quality signals
Copilot uses the Bing index as its primary source. Citation behaviour closely tracks Bing's quality signals: page authority, technical crawlability, structured data and page speed.
Step 2: Account for enterprise context
Copilot is particularly relevant in enterprise contexts where Microsoft 365 integration means it sits inside the workflow tools buyers use during vendor evaluation.
Step 3: Use Bing-friendly content structure
Content structures that perform for Bing translate directly to Copilot citation improvements: clean heading hierarchies, short paragraphs and crawlable text without JavaScript rendering.
Grok
Step 1: Build recency signals
Grok, built by xAI, draws from X/Twitter signals in addition to standard web content. Recency weighting is higher in Grok than in any other major engine.
Step 2: Connect X activity to structured content
For B2B brands active on X, consistent posts linking to structured article content create a signal pathway unique to Grok.
Step 3: Keep standard web quality strong
For brands without an X presence, Grok citation still responds to standard web quality signals.
Step 4: Refresh content more aggressively
Newer content outperforms older high-authority content more aggressively in Grok than anywhere else.
Which Content Formats Win Citations Across All Engines?
FAQ schema, question-format H2 headings, direct-answer opening paragraphs and externally cited claims are the 4 content formats that consistently perform best in Intelligent Resourcing's internal GEO Answer-First Page Framework. These are IR internal benchmark findings, not public industry averages.
The GEO Answer-First Page Framework measured the following:
FAQ schema achieves 2.7x higher citation rates than equivalent pages without structured FAQ markup. The highest single-format multiplier measured.
Question-format H2s earn an 18% citation rate versus 8.9% for statement-format H2s, a 2x difference driven by how AI extraction models scan for query-answer pairs.
Fluency combined with statistics: content that reads naturally while embedding specific named metrics outperforms either signal alone by +5.5%.
Explicit external citations produce +115% AI visibility. Pages that name the source and year of a claim are cited more frequently than pages making the same claim without attribution.
Direct quotes outperform paraphrased citations by 11 percentage points on AI citation probability.
AI extraction models discard 68% of total page content. The content that survives is concentrated in the first 500 words and in sections that match question-format patterns. For a complete implementation guide covering schema setup, direct answer blocks and heading structure, see the AI citation content structure guide.
How to Build a Citation Architecture That Compounds?
A citation architecture is a system that compounds across an entire topic cluster: each page reinforces the brand entity, links to complementary pages and builds a signal network that AI models recognise as authoritative. A single optimised page produces isolated citation events. A connected cluster produces compounding citation frequency as AI systems learn to associate the brand with a topic.
The 5 components are:
1. Entity Anchor Page
One primary page that states the company name, category, location, service description and proof in a format consistent across every other page on the site. The entity anchor is what AI systems use to resolve brand references from across the web into a single recognisable entity.
2. Question Cluster
Each topic the brand wants to be cited for requires a hub-and-spoke cluster. The hub answers the broadest version of the question and spokes answer specific sub-questions. Each spoke links back to the hub and each hub links to the relevant service page.
3. Verified Proof Layer
Every quantitative claim must link to a verifiable external source. Internal proofs require the same entity consistency: named client, named outcome, named metric, confirmed date. Claims without proof are hedged by default.
4. Technical Foundation
Server-side rendering for the first 500 words of every page, no JavaScript-gated content in the top half of any URL and JSON-LD schema that mirrors visible content exactly. Crawlable internal links between all cluster pages. GPTBot, ClaudeBot and PerplexityBot must not be blocked in robots.txt.
5. Verified Buying Window Connection
A Verified Buying Window is the period when a named account is actively evaluating vendors. It opens on a job change, a funding event, a technology shift or a hiring signal. AEO content that appears during a Verified Buying Window converts citation into pipeline. Connecting the 2 requires GTM Engineering: Clay workflows, CRM routing and signal detection alongside the content architecture.
Intelligent Resourcing's AEO/GEO service installs the full architecture inside the client's stack: entity anchor, question cluster, verified proof layer, technical foundation and Verified Buying Window detection.
How to Track Whether AI Engines Are Actually Citing You?
Track AI citation performance by running a defined set of buyer-intent prompts across ChatGPT, Perplexity, Gemini and Copilot on a monthly cycle, recording brand mention, citation with link, answer position and competitor presence per prompt. Standard GA4 and Search Console miss the majority of citation events because most AI-sourced traffic arrives as direct navigation, not a referral click.
Track 3 metrics per prompt per engine on a monthly cycle:
Mention Rate: does the brand appear in the answer at all?
Citation Rate: does the brand appear as a named hyperlinked source?
Position: is the brand mentioned first, mid-list or last in the recommended set?
Increases in mention rate that precede increases in branded search volume confirm the citation-to-pipeline pathway is active.
FAQs
How Do I Get My Website Cited by ChatGPT?
ChatGPT cites brands that exist as recognisable entities in its training corpus. Build consistent entity signals across LinkedIn, Crunchbase, industry publications and your own site. All pages must use the same company name, service category and descriptor without variation. For live retrieval, when ChatGPT browsing is active, publish direct-answer content with named external citations and question-format headings.
Does Schema Markup Help With AI Citation?
Yes for Google AI Overviews and Gemini. FAQPage and Article schema with exact parity to visible page text directly improves AI Overview citation probability. Schema impact is lower for Perplexity and Grok, where content freshness and quality signals carry more weight. For maximum cross-engine coverage, implement JSON-LD schema on all pages and maintain exact parity between schema values and visible content.
How Is AEO Different From SEO?
SEO optimises pages for search rankings and organic clicks. AEO structures content so AI systems can extract, cite and recommend a brand in generated answers. SEO targets the blue-link result. AEO targets the answer block, the citation and the shortlist recommendation. The technical foundations overlap: crawlability, domain authority, entity signals. The content structure, measurement and commercial logic are distinct.
Which AI Engine Matters Most for B2B in 2026?
ChatGPT accounts for the largest share of B2B buyer AI research, making it the highest-priority engine for most B2B brands. Perplexity rewards fresh structured content fastest; a well-built page on a credible domain earns citations within days via the IndexNow protocol. Google AI Overviews matter most for brands where buyers start research with a Google search rather than directly in an AI tool. IR's June 2026 tracker data confirms citation across all 5 engines is achievable within a structured citation programme.
How Long Before a Brand Starts Appearing in AI Answers?
Perplexity can cite newly published content within days of indexing. Google AI Overviews reflect content quality changes within 4 to 12 weeks. ChatGPT citation depends on entity recognition in the training corpus, which changes on a slower training cycle. A citation programme that runs entity establishment, structured content publishing and technical AEO in parallel produces measurable mention-rate increases within 3 months for most B2B brands with existing domain authority.